

最近,OpenAI的o1 self-play RL技术路线推演火出圈了!这波操作简直是把AI的“自我修炼”玩出了新高度,“卷”到连自己都不放过!🤯 从AlphaGo到ChatGPT,AI的进化速度堪比“光速”,而这次o1 self-play RL更是直接让AI“自己教自己”,堪称“内卷天花板”!想知道未来AI会如何“自我进化”?别急,这篇推文带你一探究竟!👉
目录导读
1. 什么是o1 self-play RL?
简单来说,就是AI自己跟自己玩!
你没听错,o1 self-play RL(自对弈强化学习)是一种让AI通过与自己对抗来提升能力的技术。就像下棋时,AI既是“黑方”也是“白方”,通过不断对弈,找到最优策略。这种“自我修炼”模式,简直是AI界的“内卷之王”!
2. 为什么o1 self-play RL这么牛?
✔️ 操作简单不费脑
✔️ 效果立竿见影
✔️ 专家都在偷偷用
o1 self-play RL的核心优势在于,它不需要大量外部数据,AI自己就能生成训练样本。这种“自给自足”的模式,不仅降低了成本,还提高了效率。难怪有人说,这是AI技术的“终极内卷”!
3. o1 self-play RL的技术路线推演
从AlphaGo到ChatGPT
AlphaGo是o1 self-play RL的“开山鼻祖”,而ChatGPT则是它的“进化版”。通过不断自我对弈,AI从“棋手”变成了“语言大师”,未来还可能成为“全能选手”!
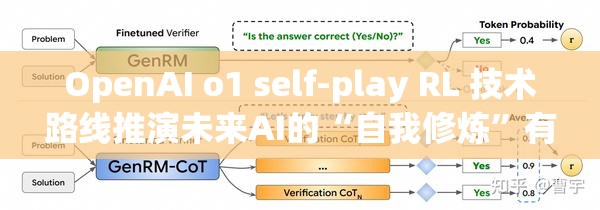
未来的技术路线
根据2025年行业报告,o1 self-play RL将在以下领域大放异彩:
- 游戏AI:从围棋到星际争霸,AI将彻底统治游戏界!
- 自动驾驶:通过自我模拟,AI将实现“零事故”驾驶!
- 医疗诊断:AI将自我学习,成为“超级医生”!
4. o1 self-play RL的“内卷”逻辑
AI的“自我修炼”有多离谱?
o1 self-play RL的核心逻辑是“自我对抗”,AI通过不断挑战自己,找到最优解。这种“内卷”模式,不仅让AI变得更聪明,还让它学会了“自我反思”!
5. o1 self-play RL的应用场景
游戏领域
从围棋到星际争霸,o1 self-play RL已经让AI成为了“游戏王者”。未来,它还可能应用于更多复杂游戏,成为“游戏界的扛把子”!
自动驾驶
通过自我模拟,o1 self-play RL将帮助自动驾驶系统实现“零事故”目标。这种“自我修炼”模式,简直是自动驾驶的“救星”!
6. o1 self-play RL的挑战与机遇
挑战
- 计算资源需求大:o1 self-play RL需要大量计算资源,成本高昂。
- 伦理问题:AI自我学习可能带来不可控的风险。
机遇
- 技术突破:o1 self-play RL将推动AI技术的进一步发展。
- 商业应用:从游戏到医疗,o1 self-play RL将带来巨大的商业价值!
7. o1 self-play RL的未来展望
AI的“自我修炼”将如何改变世界?
根据2025年行业报告,o1 self-play RL将在未来10年内彻底改变AI领域。从游戏到医疗,从自动驾驶到金融,AI将通过“自我修炼”成为各行各业的“超级助手”!
8. 常见问题(FAQ)
html
9. 总结
o1 self-play RL技术路线推演,不仅是AI的“自我修炼”,更是未来科技的“风向标”! 从游戏到医疗,从自动驾驶到金融,AI将通过“自我修炼”成为各行各业的“超级助手”。未来已来,你准备好了吗?🚀
独家观点
o1 self-play RL的“内卷”模式,不仅是AI技术的突破,更是人类智慧的延伸。未来,AI将通过“自我修炼”实现“自我进化”,成为人类最强大的“伙伴”!








 京公网安备110000000001号
京公网安备110000000001号 京ICP备110000001号
京ICP备110000001号